设z=2x+y,变量x,y满足条件x−4y≤−33x+5y≤25x≥1,求z的最大值与最小值.
 尚现杰2022-10-04 11:39:541条回答
尚现杰2022-10-04 11:39:541条回答
已提交,审核后显示!提交回复
共1条回复
 zhnlove2003 共回答了17个问题
zhnlove2003 共回答了17个问题 |采纳率100%- 解题思路:根据已知中的约束条件,画出满足
的平面区域,并画出满足条件的可行域,由图我们易求出平面区域的各角点的坐标,将角点坐标代入目标函数易判断出目标函数2x+y的最大值和最小值.x−4y≤−3 3x+5y≤25 x≥1 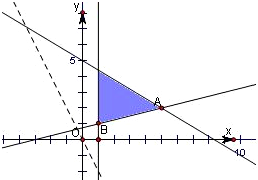 满足
满足
x−4y≤−3
3x+5y≤25
x≥1的平面区域如下图所示:
由图可知,当直线z=2x+y经过点A(5,2)时,即当x=5,y=2时,2x+y取得最大值12,
同理,当x=1,y=1时,2x+y取得最小值3.
故z的最大值与最小值分别为:12和3.点评:
本题考点: 简单线性规划.
考点点评: 本题考查的知识点是简单线性规划,画出满足条件的可行域及各角点的坐标是解答线性规划类小题的关键. - 1年前

相关推荐
- 谁能把自变量和因变量说清楚 我不明白书本上看不懂 我是初一的学生
06243877631年前1
-
卉坚 共回答了21个问题
|采纳率90.5%首先,自变量和因变量均是变量,也就是说它们并不是确定不变的数(或量).自变量可以自由改变,因变量是随着自变量的变化而变化.自变量的变化导致了因变量的变化,因变量和自变量之间存在某种对应关系.例如,你吃饭量(自...1年前查看全部
- 变量U与V相对应的一组样本数据为(1,1.4),(2,2.2),(3,3),(4,3.8),由上述样本数据得到U与V的线
变量U与V相对应的一组样本数据为(1,1.4),(2,2.2),(3,3),(4,3.8),由上述样本数据得到U与V的线性回归分析,R2表示解释变量对于预报变量变化的贡献率,则R2=( )
A.[3/5]
B.[4/5]
C.1
D.3hotboy2101年前0 -
共回答了个问题
|采纳率
- 为了考察两个变量x和y 为了考察两个变量x和y之间的线性相关性.甲、乙两位同学各自独立地做10次和15次试验,并且利用线
为了考察两个变量x和y
为了考察两个变量x和y之间的线性相关性.甲、乙两位同学各自独立地做10次和15次试验,并且利用线性回归方程,求得回归直线分别为l 1 和l 2 .已知两个人在试验中发现对变量x的观测数据的平均值都是s,对变量y的观测数据的平均值都是t,那么下列说法正确的是 [ ] A.l 1 与l 2 相交点为(s,t)
B.l 1 与l 2 相交,相交点不一定是(s,t)
C.l 1 与l 2 必关于点(s,t)对称
D.l 1 与l 2 必定重合zyxk19731年前1 -
牛牛强强 共回答了22个问题
|采纳率100%A1年前查看全部
- 求下列函数的最大值和最小值,并求出自变量X的相应的取值:y=4-1/3sinx y=2+3cosx
H-Jasper1年前1
-
111海角111 共回答了18个问题
|采纳率94.4%(1)x=2k*pi+pi/2时取最小値11/3;x=2k*pi+3/2*pi时取最大值13/3;
(2)x=2k*pi时取最大值5;x=2k*pi+pi时取最小值-1;1年前查看全部
- 某同学在两个同样的花盆中种下大豆种子,并设计了如下的实验。从该实验可知:他在研究的影响大豆发芽的因素和变量是 [
某同学在两个同样的花盆中种下大豆种子,并设计了如下的实验。从该实验可知:他在研究的影响大豆发芽的因素和变量是  [ ]
[ ]A.阳光
B.空气
C.温度
D.水分想T就T1年前1 -
xqhwc1234 共回答了18个问题
|采纳率100%D1年前查看全部
- 关于无穷小概念的几个问题1,变量和函数有什么区别?2,是不是在x取到某个值x0使变量等于0,不管x0可取到是1个还是多个
关于无穷小概念的几个问题
1,变量和函数有什么区别?
2,是不是在x取到某个值x0使变量等于0,不管x0可取到是1个还是多个,变量都是无穷小?
3.如果2成立,则x²和(x-1)²都是无穷小,但x²+(x-1)²非无穷小,rouwen20061年前2 -
dzdejn 共回答了15个问题
|采纳率86.7%1、变量是指不确定数值的量,和常数这个概念相对应.而函数就是两个或多个变量之间的关系式.2、无穷小的概念是由极限推理出来的.当函数f(x)在x趋近于x0的时候,f(x)趋近于0,那么就说f(x)是x趋近于x0时的无穷小.所...1年前查看全部
- 在用SPSS进行logistic二元回归时,一直说我因变量的非缺失值少于两个.怎么改
在用SPSS进行logistic二元回归时,一直说我因变量的非缺失值少于两个.怎么改
我把ST公司设置为1,非ST公司设置为0的
 敏而不gg1年前2
敏而不gg1年前2 -
foreverwithu 共回答了16个问题
|采纳率93.8%你选择的因变量是不是只用一个值,要么都是1,要么都是0,你检查下1年前查看全部
- VB中表示条件“变量X为能被7整除的奇数”的逻辑表达式是
小董4261年前1
-
abccx176 共回答了21个问题
|采纳率66.7%x mod 7 = 0 and x mod 2 = 1
或
x mod 7 = 0 and x mod 2 0
因为vb中,优先级为"and">"=">"mod"
故无需加括号.
这段内容返回一个Boolean类型的值.即返回True或False,可直接加进if...then语句中
语句中部分空格vb会自动加.1年前查看全部
- 统计学选择题:若计算出某变量分布的峰度系数值为1.8,则判断该分布属于( ).
统计学选择题:若计算出某变量分布的峰度系数值为1.8,则判断该分布属于( ).
A.尖峰分布 B.扁平分布 C. 峰度适中 D.无法判断ailaure331年前1 -
duba1985 共回答了17个问题
|采纳率82.4%B1年前查看全部
- 编一个程序,定义一个双精度浮点数变量,从键盘输入一个数,判定它是否在[500,1200]的区间里.
编一个程序,定义一个双精度浮点数变量,从键盘输入一个数,判定它是否在[500,1200]的区间里.
急.要涨就涨停1年前1 -
英语班三十二号 共回答了23个问题
|采纳率82.6%c
main()
{ double a;
scanf("%lf",&a);
if(a>=500&&a1年前查看全部
- 怎样理解这些VB题目1.在过程中已说明a、b、c均为Integer型变量,且均已被赋值,其中a=30、b=40、C=50
怎样理解这些VB题目
1.在过程中已说明a、b、c均为Integer型变量,且均已被赋值,其中a=30、b=40、C=50,如再执行下面的语句,可正常执行的是___________。
A.Print a*b*c B.Print a*b*c*1&
C.Print 1&*a*b*c D.Print a*b*c*1!
2.某过程的说明语句中,正确的数组说明语句是__________。
Const N As Integer=4
Dim L As Integer
①Dim X(L) AS Integer
②Dim A(K) As Integer
Const K As Integer=3
③Dim B(N) As Integer
④Dim Y(2000 to 2008) As Integer
A.①②④ B.①③④ C.③④ D.②③
我需要解释,答案我知道,两个都是C ,请高手帮帮忙啊。我比芙蓉ll漂亮1年前1 -
playfox 共回答了22个问题
|采纳率104.5%1.c a.b.d 都会溢出
2.c,数组参数要先定义1年前查看全部
- 用智慧LOGO画圆.要用递归,要用到变量,要命令.起始边长(半径)是10,边长每次增加1,最长边长是200
ss斗1年前1
-
4501458 共回答了25个问题
|采纳率96%to yuan:n
if :n>200 then stop
fd :n
yuan :n+1
end
yuan 101年前查看全部
- C++问题 若有下面的变量定义,以下语句中合法的是
C++问题 若有下面的变量定义,以下语句中合法的是
若有下面的变量定义,以下语句中合法的是
int i, a[10],*p;
a.P=a+2
b.p=a[5]
c.p-a[2]+2
d.p=&(i+2)
跪求答案和解释
检讨ING1年前1 -
立威廉 共回答了21个问题
|采纳率90.5%a. p=a+2 a是指针 p是指针 p=a+2合法,不过题中P大写不正确
b.p=a[5] 类型不匹配
c.p-a[2]+2 类型不匹配
d.p=&(i+2) 不能取表达式地址1年前查看全部
- 有关于非独立变量的中心极限定理林德贝格菲勒定理要求变量是独立的,有没有非独立变量的中心极限定理呢?
带枪的红狐狸101年前1
-
haihun521 共回答了25个问题
|采纳率88%随机变量不独立的时候和就没有正态特征了,就没有中心极限定理了.条件最宽松的中心极限定理就是李雅普诺夫中心极限定理了,它要求独立但可以不同分布.另外从总体和样本的角度看待中心极限定理的应用,样本都是独立同分布的.1年前查看全部
- 甲乙两同学对关于变量xy 的抛物线f Y=x的平方-2mx+2m的平方+2m
甲乙两同学对关于变量xy 的抛物线f Y=x的平方-2mx+2m的平方+2m
甲、乙两同学对关于y、x的抛物线f:y=x2-2mx+2m2+2m进行探讨交流时,各得出一个结论.
甲同学:当抛物线f经过原点时,顶点在第三象限平分线所在的直线上;
乙同学:不论m取什么实数值,抛物线f顶点一定不在第四象限.
(1)请你求出抛物线f经过原点时m的值及顶点坐标,并说明甲同学的结论是否正确?
(2)乙同学的结论正确吗?若你认为正确,请求出当实数m变化时,抛物线f顶点的纵横坐标之间的函数关系式,并说明顶点不在第四象限的理由;若你认为不正确,求出抛物线f顶点在第四象限时,m的取值范围.lionel10261年前2 -
瘦瘦飞 共回答了14个问题
|采纳率85.7%(1)抛物线f经过原点时,2m2+6m=0 则:m1=7或 m2=-1
∴当m=-1时抛物线f表达式为y=x2+2x顶点(-1,-1),
当m=0时抛物线f表达式为y=x2,顶点(0,0)
由于顶点(-a,-a)和顶点(0,0)都在第三象限的平分线所在的直线上,
∴甲同学结论正确,
(2)乙同学的结论正确,
∵抛物线a的解析式y=x2-2mx+2ml+2m可变为y=(x-m)2+m2+2m
∴抛物线f的顶点为(m,m2+8m),若设抛物线f的顶点为(x,y)
则:{_y=m2+2mx=m,
∴抛物线f顶点的纵横坐标的函数关系式为:y=x2+2x,
又由于抛物线y=x2+2x的顶点为(-0,-0),与x轴的交点为(0,0),(-2,0),
抛物线开口向上.∴抛物线y=x2+2x不可能在第四象限.
即:不论m取什么实数值,抛物线f顶点一定不在第四象限.1年前查看全部
- 给出下列结论:(1)两个变量之间的关系一定是确定的关系;(2)相关关系就是函数关系;(3)回归分析是对具有函数关系的两个
给出下列结论:
(1)两个变量之间的关系一定是确定的关系;
(2)相关关系就是函数关系;
(3)回归分析是对具有函数关系的两个变量进行统计分析的一种常用方法;
(4)回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法.
以上结论中,正确的有几个?( )A.1 B.2 C.3 D.4 水中仙3431年前1 -
牛奶面包电脑 共回答了18个问题
|采纳率94.4%(1)个变量之间的关系不一定是确定的关系,这是一个不正确的结论.
(2)相关关系是一种非确定性关系,相关关系不是函数关系,这是一个不正确的结论.
(3)回归分析是对具有相关关系的两个变量进行统计分析的一种方法,所以(3)不对.
与(3)对比,依据定义知(4)是正确的,
故选A.1年前查看全部
- 下列命题:①线性相关系数r越大,两个变量的线性相关性越强;反之,线性相关性越弱;②残差平方和越小的模型,拟合效果越好;③
下列命题:
①线性相关系数r越大,两个变量的线性相关性越强;反之,线性相关性越弱;
②残差平方和越小的模型,拟合效果越好;
③用相关指数R2来刻画回归效果,R2越小,说明模型拟合效果越好;
④随机误差e是衡量预报精确度的一个量,它满足E(e)=0.
其中正确的是______(填序号).阿米七1年前1 -
imissyou21cn 共回答了12个问题
|采纳率91.7%解题思路:线性相关系数|r|越大,两个变量的线性相关性越强,残差平方和越小的模型,拟合的效果越好,用相关指数R2来刻画回归效果,R2越大,说明模型的拟合效果越好,根据对于随机误差的理解得到④正确.线性相关系数|r|越大,两个变量的线性相关性越强;故①不正确,
残差平方和越小的模型,拟合的效果越好,②正确
用相关指数R2来刻画回归效果,R2越大,说明模型的拟合效果越好,③不正确,
随机误差e是衡量预报精确度的一个量,它满足E(e)=0.④正确,
总上可知②④正确,
故答案为:②④.点评:
本题考点: 相关系数.
考点点评: 本题考查两个变量的线性相关和线性回归方程,本题解题的关键是理解对于拟合效果好坏的几个量的大小反映的拟合效果的好坏,用来描述拟合效果好坏的量比较多,注意各个量的区别,本题是一个基础题.1年前查看全部
- 解析几何的一个定理空间中任一平面的方程都可表示成一个关于变量x,y,z的一次方程;反过来,每一个关于变量x,y,z的一次
解析几何的一个定理
空间中任一平面的方程都可表示成一个关于变量x,y,z的一次方程;反过来,每一个关于变量x,y,z的一次方程都表示一个平面.天下无功1年前2 -
m162000cn 共回答了11个问题
|采纳率81.8%应该是正确的,楼上的举例实质上是一个方程组写在一起的1年前查看全部
- 微分方程 分离变量,为什么右边两边积分后+的ln|c|?
chenhaocyj1年前2
-
yuanzhj 共回答了16个问题
|采纳率93.8%可以不用lnC的,那是为了去掉对数的方便,这是微分方程的一个习惯.
你那例子:
ln|f(y)|=-ln|g(x)|+C1
ln|f(y)|+ln|g(x)|=C1
|fg|=e^(C1)
fg=±e^(C1)=C
一般讲,凡是积分后有对数且想去掉对数的,常数都可以写成ln|C|甚至lnC1年前查看全部
- 已知一正比例函数,因变量y增加3时,自变量x增加9,则此函数的关系式为
tianyu24301年前1
-
dty_829 共回答了20个问题
|采纳率90%设该正比例函数为y=kx,由因变量y增加3时,自变量x增加9可得y+3=k(x+9)
联立两式解得k=1/3,即该正比例函数关系式为y=1/3x1年前查看全部
- 函数y=x³中,变量和常量分别是什么?
函数y=x³中,变量和常量分别是什么?银狐望月1年前3
-
针扎的痛 共回答了16个问题
|采纳率93.8%似乎常量只是一1年前查看全部
- 两个变量成反比例,则它们的积一定是
飘伶人1年前1
-
酷鱼 共回答了16个问题
|采纳率81.3%两个变量成反比例,则它们的积一定是一个非零常数:
Y = K / X X ≠ 0 K ≠ 0;
XY = K .1年前查看全部
- dy/dx +y/x=lnx 求微分方程,如何变量分离
tigertiger0071年前2
-
那德福祥 共回答了16个问题
|采纳率81.3%这不好变量分离,它是一阶线性微分方程,有公式的
解为:y'=-1/x*(∫ xlnxdx+C)=-1/x*(∫ lnxd(x^2/2)+C)=-1/x*(lnx*(x^2/2)-∫ x/2dx+C)
=-C/x+x(2lnx-1)/41年前查看全部
- 数据结构算法问题已知Q是一个非空队列,S是一个空栈.仅仅用队列和栈的基本函数和少量工作变量,设计一个算法,将队列Q逆置,
数据结构算法问题
已知Q是一个非空队列,S是一个空栈.仅仅用队列和栈的基本函数和少量工作变量,设计一个算法,将队列Q逆置,(今晚刚看到的一个题,死活没头绪,求详细解答,非常感谢)天山一枝梅1年前1 -
飘玲 共回答了18个问题
|采纳率83.3%将队列中元素按序取出并放入栈中,然后再逐一出栈并插入回队列中,就完成了逆置.1年前查看全部
- 时间序列分析中,通常把因变量的变化看成是趋势项,波动项、季节项等的合成,这些项中哪些是可省的,哪些是不可省的.如果同样的
时间序列分析中,通常把因变量的变化看成是趋势项,波动项、季节项等的合成,这些项中哪些是可省的,哪些是不可省的.如果同样的问题,同样的数据,都采用时间序列分析,那么不同的人得到的结果会相同吗?急,急!
丑丑爱美丽1年前1 -
zhiweiai 共回答了19个问题
|采纳率94.7%时间序列分析是一个很大的分类,包括很多模型,分别适用于不同的情况.所以得到的结果一不一样和建的模型一不一样有关系.至于模型长什么样要看数据长什么样.把数据按时间画出来,看有没有明显趋势,波动或者季节性,然后一个一个模型试.1年前查看全部
- 下列说法正确的是:A.在确定的电场中移动电荷时,电势能的改变量同零电势点的选择无关
下列说法正确的是:A.在确定的电场中移动电荷时,电势能的改变量同零电势点的选择无关
B.在确定的电场中,电荷所具有的电势能同零电势点的选择无关
C.电势能是电场和电场中电荷共有的能
D.电势能只是电场中的电荷所具有的能pkulin20001年前3 -
sh1985 共回答了12个问题
|采纳率83.3%A正确,因为电势对于零电势点是相对的,电势能的改变量与电场做功的大小相等,是绝对的.
B不正确,电荷所处点的电势与零电势点选择有关,而电势能=电势×电量
C正确,电势能是电场和电场中的电荷共有的能
D不正确,理由同C
希望我的回答可以解决您的问题!1年前查看全部
- 一次函数应用题怎么求取值范围举个例题谢谢(函数与变量).
不kk不kk1年前1
-
qycjh 共回答了20个问题
|采纳率85%这个····有点难吧····1年前查看全部
- 线性回归分析中为什么把解释变量假设为非随机变量,
wangying980410381年前2
-
6目 共回答了16个问题
|采纳率100%因为是现行回归了,
比如对于两个变量的,x,y,
假设了用解释变量x的方程式表示y,
此时只有确定x,才能有对应的y预测值
因此x此时不是随机变量,1年前查看全部
- 平均值的标准偏差 怎么算,要公式和各个变量的含义!
zoelucky1年前1
-
gg9a 共回答了24个问题
|采纳率83.3%平均值的标准偏差时相对于单次测量标准偏差而言的,在随机误差正态分布曲线中作为标准来描述其分散程度:
在一定测量条件下(真值未知),对同一被测几何量进行多组测量(每组皆测量N 次),则对应每组N 次测量都有一个算术平均值,各组的算术平均值不相同.不过,它们的分散程度要比单次测量值的分散程度小得多.描述它们的分散程度同样可以用标准偏差作为评定指标.根据误差理论,测量列算术平均值的标准偏差σχ 与测量列单次测量值的标准偏差σ 存在如下关系
σχ=σ /√n
----------------------
单次测量标准偏差:(贝塞尔公式计算)见图片
残余误差νi 即测得值与算术平均值之差
N:测量次数1年前查看全部
- 已知两个变量x与y之间具有线性相关关系,5次试验的观测数据如下:
已知两个变量x与y之间具有线性相关关系,5次试验的观测数据如下:
那么变量y关于x的回归直线方程只可能是( )x 100 120 140 160 180 y 45 54 62 75 92 A.
=0.575x-14.9
y B.
=0.572x-13.9 y C.
=0.575x-12.9 y D.
=0.572x-14.9 y su-3101年前1 -
tianyi0802 共回答了21个问题
|采纳率90.5%计算出横标和纵标的平均数:
.
x =140 ,
.
y =65.6 ,
代入回归直线方程检验:
A:适合此方程.
线性回归方程
y =
b x+
a 必过样本中心点,
故A正确.
故选A.1年前查看全部

- eviews 分析中各个变量间的计算关系
心只有你11251年前1
-
xinyu52115 共回答了14个问题
|采纳率92.9%估计值的标准差是衡量回归系数的稳定性和可靠性的,如果较小说明系数的稳定性较好;
估计值的T值是检验系数是否为零,可查表得到相应的临界值,如果T值大于临界值则系数在对应的显著水平(1%.5%.10%)上是可靠的;
估计值显著性概率值表示在t分布下,t统计量的概率值.在5%显著水平下,如果该概率值低于0.05则说明系数值在统计上是显著的.
R方表示回归的拟合成都.取值范围在0-1之间,越接近1则拟合程度越好;
调整的R方:随着解释变量的增加,R方只会增加不会减少.为了对增加的解释变量进行惩罚,要对R方调整
D-W:衡量回归误差是不是序列相关,该统计量如果严重偏离2,则说明存在序列相关
F统计量用于衡量回归方程整体显著性的假设检验1年前查看全部
- 关于加速度a的一个疑问我们都知道,加速度a是速度v对于时间变量t的变化量.其单位为:m/s^2.现在提出一个量:b,令b
关于加速度a的一个疑问
我们都知道,加速度a是速度v对于时间变量t的变化量.其单位为:m/s^2.
现在提出一个量:b,令b为v在加速度为a的情况下对于距离s的变化量.其单位为:1/s.
简单来说b就是在某个运动瞬间,速度v每米的变化量.
现求b的数学表达式.
ps,可以加入的变量如下:v0,t.gudaoyeying1年前1 -
田田89109 共回答了23个问题
|采纳率87%=v(s)'=(s/t)'=1/t1年前查看全部
- 积分求曲形面积积分求解曲形面积时,何时用x做变量,何时用y做变量?
xb528555001年前1
-
240057842 共回答了15个问题
|采纳率73.3%什么吗1年前查看全部
- 一道关于初中函数的题变量x.y.z均不小于0 并且满足3y+2z=3-x及3y+z=4-3x 求函数w=3x-3y+4z
一道关于初中函数的题
变量x.y.z均不小于0 并且满足3y+2z=3-x及3y+z=4-3x 求函数w=3x-3y+4z的最大值和最小值.yushuaaa19801年前2 -
gtly_1966 共回答了21个问题
|采纳率95.2%由3Y+2Z=3-X及3Y+Z=4-3X解得:
y=(5-5x)/3
z=-1+2x
又:y>=0得:(5-5x)/3>=0
x=0得:-1+2x>=0
x>=1/2
又:x>=0
综上:1/21年前查看全部
- 有关概率密度求随即变量X落在某区间的概率的问题
有关概率密度求随即变量X落在某区间的概率的问题
设随机变量X的概率密度为f(x)=2x,0男人穿袜子1年前2 -
tears210 共回答了11个问题
|采纳率81.8%f(x)=2x的积分函数为x的平方,因此1/2的平方减去0的平方为1/4.就是答案.1年前查看全部
- 声明一个数组,他的元素个数一定是要常量吗 还是可以变量?就是中括号里填写的内容
bob936661年前1
-
蝴蝶飞-女 共回答了17个问题
|采纳率88.2%可以是数字,也可以是宏定义的宏,不能是变量.1年前查看全部
- A1-A10,B1至B10,C1至C10,D1至10其中A,B,C为变量当A1,B1,C1三格有任意两数字相同D1录入0
A1-A10,B1至B10,C1至C10,D1至10其中A,B,C为变量当A1,B1,C1三格有任意两数字相同D1录入0反之则从1序列填充不可为而为之1年前2
-
女木鱼 共回答了17个问题
|采纳率94.1%将D列作为辅助列
D1输入公式 =IF(OR(A1=B1,A1=C1,B1=C1),0,1)
下拉
E1输入公式 =IF(D1=0,0,SUM(D$1:D1))
下拉即可,E列即为结果1年前查看全部
- 在SQL Server中,下列变量名正确的是( A、@sum B、j C、sum D、4kk
山上的云1年前1
-
dove13 共回答了18个问题
|采纳率94.4%A1年前查看全部
- 设Z=x-y,式中变量x和Y满足条件{x+y-3≧0} {x-y≧0}则Z的最小值为() A:1
设Z=x-y,式中变量x和Y满足条件{x+y-3≧0} {x-y≧0}则Z的最小值为() A:1
设Z=x-y,式中变量x和Y满足条件{x+y-3≧0}
{x-y≧0}则Z的最小值为()
A:1
B:-1
C:3
D:-3彩八哥1年前1 -
悠悠之口 共回答了25个问题
|采纳率96%C1年前查看全部
- 为什么i<10而不是i<20?i不是循环变量吗?
为什么i<10而不是i<20?i不是循环变量吗?
1,1,2,3,5,8,13..这一数列的规律是:第1第2个数是1,从第三个数起,该是前面两个数之和,试画出计算这列数前20个数之和的程序框图,并写出程序.

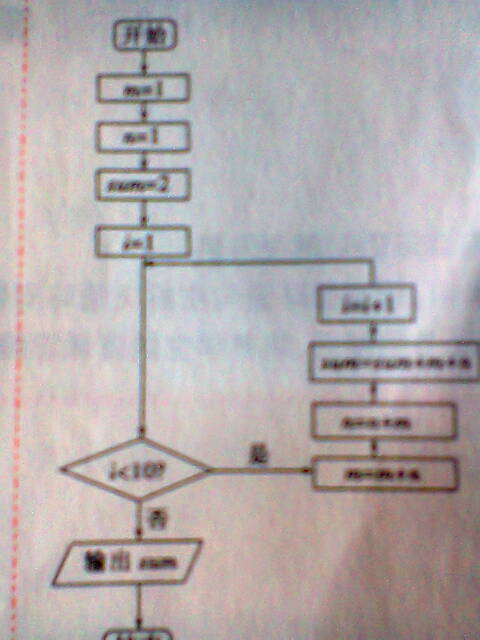
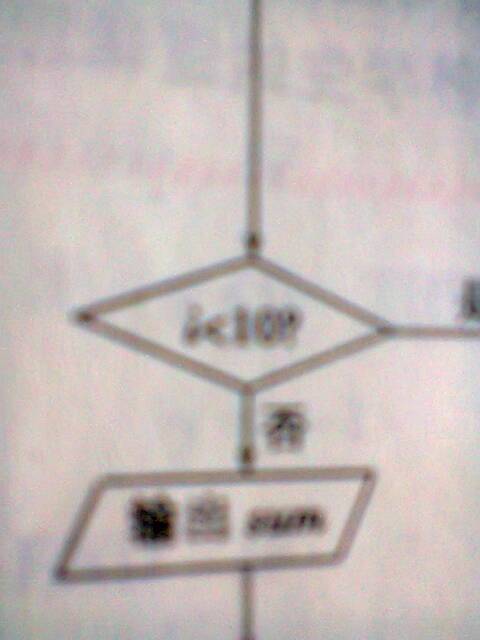 809151年前1
809151年前1 -
狂吻 共回答了12个问题
|采纳率100%1 1 2 3 5 8 13
注意看
m=m+n ‘第一步
n=n+m ’第二步
sum=sum+m+n
总共循环9次,但是每次循环里都会执行两步,就相当于执行了18次 . 循环的18次加上前面的两个 1,刚好是第20个数字
当m=1
n=1
sum=2时
1;
m=m+n=1+1=2
n=n+m=1+2=3
2;
m=m+n=2+3=5
n=n+m=3+5=8
然后你再对比上面的 1,1 2,3 5,8 .
你应该会发现什么的.1年前查看全部
- 一次函数y=kx+b,当变量x的取值范围是2≤x≤4,函数y的取值范围是-1≤x≤2,求一次函数y=kx+b的解析式.
星蓝KIKI1年前1
-
浪子遇上真爱 共回答了18个问题
|采纳率88.9%因为是一次函数即直线,所以在端点取得最值,所以函数过点(2,-1),(4,2)解得y=1.5x-41年前查看全部
- 为什么T要赋予它1的值,I要赋予它2的值,计数变量到底是什么?(关于此例题)为什么每循环一次I增加1?
为什么T要赋予它1的值,I要赋予它2的值,计数变量到底是什么?(关于此例题)为什么每循环一次I增加1?
例题:写出求1×2×3×4×5的一个算法,并画出流程图.
解:S1 T“=”(赋值语句的符号)1
S2 I“=”2
S3 如果I≤5,那么转S4,否则转S6;
S4 T“=”T×I;
S5 I “=” I +1,转S3;
S6 输出Tmatec20041年前1 -
爱琴海的珍珠522 共回答了18个问题
|采纳率83.3%I是计数变量,也就是控制运算次数的,I的赋值你完全可以自己定义,不是唯一的,这里用I=2,是为了简化程序,让I既做计数变量,又可以用来参与运算---S4 T“=”T×I;
T赋予1是因为要从1连乘到5,其实你也可以把程序倒过来写,从5连乘到1
S1 T“=”(赋值语句的符号)5
S2 I“=”4
S3 如果I大于等于(懒得找符号) 1,那么转S4,否则转S6;
S4 T“=”T×I;
S5 I “=” I -1,转S3;
S6 输出T1年前查看全部
- 根号下的变量应该怎么求导呢?
toproad1年前2
-
yixiu134 共回答了17个问题
|采纳率76.5%f(x)=√g(x)=[g(x)]^(1/2)
所以f'(x)=1/2*[g(x)]^(-1/2)*g'(x)
即f'(x)=1/[2√g(x)]*g'(x)1年前查看全部
- 英语翻译第一步:开始,输入n第二步:如果n小于2,则设标志变量flag为0,否则设flag为1第三步:置i为2第四步:当
英语翻译
第一步:开始,输入n
第二步:如果n小于2,则设标志变量flag为0,否则设flag为1
第三步:置i为2
第四步:当i小于等于n/2且flag为1时,进入第五步,否则进入第八步.
第五步:置a为n除以i的余数
第六步:如果a=0,置flag为0,否则置i为i+1
第七步:转到循环判断,即第四步.
第八步:如果flag为1,输出is prime,否则输出is not prime
第九步:算法结束.
提示:条件中并且用:and,或者用:or,否定用:not,求余数运算用:mod
 求正确的写法上下都要.还有帮忙看下我的有木有错误,thx 朱爱小白1年前1
求正确的写法上下都要.还有帮忙看下我的有木有错误,thx 朱爱小白1年前1 -
严锐 共回答了9个问题
|采纳率88.9%这个太专业啦,我只能帮你顶一顶,希望有高手为你解答1年前查看全部
- 若变量x,y满足约束条件x+
一个人的qq1年前2
-
猛蛇神 共回答了25个问题
|采纳率84%哈哈.真搞笑x0d作出2x+y=3,x-y=6的半区间的交集,知x+2y的最小值是在2x+y=3和x-y=9的交点,求出得:x=4,y=-5.故z=x+2y的最小值为4-2*5=-61年前查看全部
- 求∫上x下0 f(x-t)dt 对x的导数.做变量替换u=x-t后,dt不知道怎么变
求∫上x下0 f(x-t)dt 对x的导数.做变量替换u=x-t后,dt不知道怎么变
dt不知道怎么变
dt=d(x-u)然后呢?不理解为什么是dt=-du 应该是dt=dx-du啊.electricpower1年前3 -
启迪人 共回答了17个问题
|采纳率94.1%解答:
做变量替换u=x-t后,先前的变量是t,
而还原后的变量是u,x相当于一个常数,
所以d(x-u)=dx-du=0-du=-du1年前查看全部
- 线性规划问题的可行解是指满足什么的一组变量的值?急
山雅1年前1
-
梦栀凌 共回答了19个问题
|采纳率94.7%域为凸集.参考二维问题的图解法,其可行域是由几个线条围起来的区域,所以肯定是凸集.那么,求解最优解就在这个凸集里搜索.由目标函数等值线的移动来搜索解,则最优解肯定在其凸集的边缘达到最优值,而该凸集的边缘要么是线段要么是顶点,因此线性规划问题的最优解肯定是在可行域的顶点上.
其实这些顶点就是线性规划问题的基可行解.
那么怎么从模型中求出这些顶点(基可行解)呢?
求解模型的关键在于求解AX=b.
因A矩阵为m×n矩阵,无法得出上述约束条件方程的唯一解.必须在A矩阵中找出m×m的非奇异子矩阵B,即满足|B|不等于零(行列式不为零),从而可求得BX=b的唯一解.此时对应于矩阵B的决策变量称为基变量,其余为非基变量.X中基变量取值为BX=b的解,非基变量取值为零,则该X即为问题的基(可行)解,即对应于可行域的顶点的解.
这是按我的理解写的,希望能有所帮助.
另外,团IDC网上有许多产品团购,便宜有口碑1年前查看全部
- 线性规划中为什么自由变量可以令其等于两非负变量之差
213771年前1
-
神斗士--隆美尔 共回答了18个问题
|采纳率88.9%热心问友 2012-09-17肯定可以啊.只要是等价关系且不影响结果,你给出的条件都可以.你说的那个是为了让变量都是正数而设定的.追问:那两非负变量之差就可以保证是正数吗?回答:不可以,实际上,两非负变量之差可以去到任意值.所以才才令自由变量等于两非负变量之差,这样就可以保证自由变量的取值是R 追问:谢谢您的回答.但是,我还是不太明白,我们的目的是化为标准型,标准型要求xj>=0 (,j=1,2,3.) 既然两非负变量之差不能保证是非负,而自由变量又是这两个变量的差,那就是说自由变量不能保证是非负了,那与标准型定义矛盾啊 新手望多指教 回答:变换之后自由变量就没有了.剩下的都是非负的变量.1年前查看全部
- conditional的译法Variables and conditional texts译为变量以及条件性文本恰当么,
conditional的译法
Variables and conditional texts译为
变量以及条件性文本恰当么,或者conditional翻译为临时性文本xicewolf1年前3 -
佑被糗了 共回答了16个问题
|采纳率93.8%我觉得你译为临时性文本就不错,英文意思大家都明白,翻译为中文时根据上下文情况看,只要贴切就行,没有具体的标准答案(除非它是专业术语).嘿嘿!1年前查看全部
大家在问
- 1我正逐渐习惯这里的天气 I____ _____ ______ ______ the weather here.在短时间内
- 2牛顿和爱迪生谁贡献大?
- 3在人们吃的米饭、花生、鸡蛋中,能为机体提供能量的物质包括( )
- 4王强买了5支笔和8个本,已知每只笔比本便宜0.1元,他共花了7.3元,问笔的价钱?
- 5江西金太阳试卷数学卷求:全国100所名校单元测试示范卷·高三·数学卷(十一)——第一轮总复习用卷(新课标)江西金太阳教育
- 6把一个体积为100cm3的塑料球放入盛满水的杯中,漂浮在水面上,排开水的体积是80cm3,杯底所受的压强比起原来____
- 7宇宙里是高质量恒星多还是低质量恒星多?
- 8一次函数y=kx+b的图象过点(m,1)和(1,m)两点,且m>1,则k=______,b的取值范围是______.
- 9x趋于0时,ln(1+x)-(ax∧2+bx)是x∧2的高阶无穷小,求ab的值
- 10已知数列{an}和{bn}满足:a1=1,a2=2,an>0,bn=跟号an*a(n+1)(n€R)
- 11"我一个人过得很好"用英文怎么说
- 12一质量为m的小物块沿半径为R的固定圆弧轨道下滑,滑到最低点时的速度是v,若小物块与轨道的动摩擦因数是μ,则当小物块滑到最
- 13某人有 360元钱,其中5元张数是2元张数的80%,五元和二元各有多少张?
- 14)已知两个因数的积是12.7,如果一个因数不变,另一个因数乘10,这时两个因数的积是
- 15(10分)某课外活动小组研究金属钾的性质。他们通过Na、K原子结构示意图及查找有关资料,知道了Na、K属于同一类物质,且